19 octobre 2025
Temps de lecture : 3 min

Cet été, je suis tombée sur “L’étrange Plume de ChatGPT”, une tribune signée Francis Kaplan, professeur d’humanités numériques à l’EPFL.
Kaplan y décortique le style de la machine, cette prose sous stéroïdes rhétoriques qui recycle notamment deux figures à la chaîne : le diptyque pivot, « ce n’est pas ceci, c’est cela », et le triptyque rythmique, ce petit crescendo en trois temps qui donne du peps aux phrases.
Si la machine affectionne ces tours, c’est qu’ils abondent dans les corpus dont elle se nourrit.
Comprenez : faciles à enchaîner, ils forment un modèle stylistique clé en main. Mais leur répétition mécanique finit par user le lecteur : la prose devient lisse, l’intonation monotone, et notre sens de l’émerveillement finit par s’émousser. Cette homogénéité s’infiltre partout : dans les tournures, le vocabulaire, la syntaxe, jusqu’à la structure même du texte.
Et cela se perçoit dès l’accroche. Vous voyez ? Ces phrases tampons qui prétendent situer le propos et finissent par ne rien dire du tout :
« À l’heure où le numérique bouleverse nos repères… »
« Dans un monde en perpétuelle mutation… »
« Plus que jamais, il est crucial de repenser… »
Ensuite, vient cette manie du double effet kiss-cool : une idée qui se veut forte, suivie aussitôt d’une reformulation grandiloquente :
« L’enjeu dépasse la simple innovation technique — il redéfinit les contours mêmes de notre rapport au monde. »
Souvent, la même idée refait surface, déguisée sous mille formulations. À croire qu’un courant discret, sous la surface, nous ramène toujours au même point.
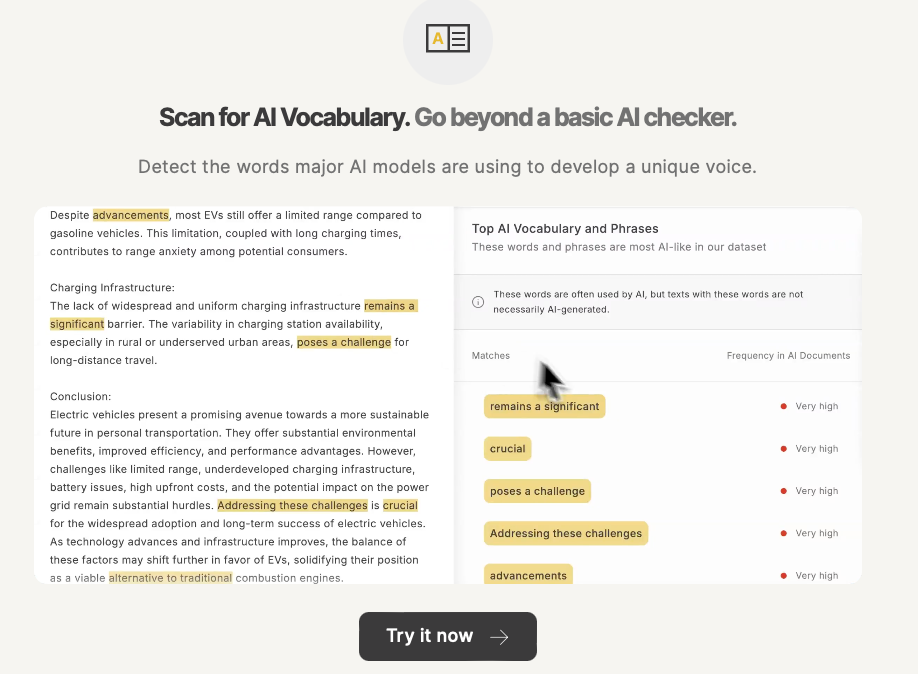
Ajoutez à cela la série incontournable de participes présents, tels que ‘en révélant’, ‘en mobilisant’, ‘en anticipant’, qui flottent dans un ton désincarné et vaguement expert. Les tirets cadratins, pour leur part, truffent les outputs des machines pour introduire des détails … souvent inutiles. Quant aux adjectifs – crucial, pertinent, nécessaire, complexe et tutti quanti-, ils viennent colmater ce que le fond ne porte pas. CQFD.
Bien que des outils promettent de repérer les textes écrits par l’IA, leur fiabilité reste relative. Rawad Baroud, CEO de GPTZero, explique que la détection dépend de nombreux facteurs : la longueur du texte, la langue et surtout le degré de mélange entre écritures humaines et générées.
Techniquement, son modèle repose sur une double analyse : une couche sémantique, issue d’un transformeur entraîné à reconnaître le style et la cohérence du discours, et une couche statistique, fondée sur la vraisemblance lexicale et la mesure d’entropie. Ces deux signaux sont ensuite fusionnés pour produire un score de probabilité et une visualisation des segments les plus « machiniques ».
GPTZero ne rend donc pas de verdict tranché : « Les détecteurs ne sont pas des polygraphes », rappelle Baroud. « Ils ne prennent sens que replacés dans un contexte. »
Et quand on lui demande comment reconnaître la main d’une IA, Baroud invite à revenir aux fondamentaux : regarder les sources, les dates, les éléments concrets ; scruter les détails secondaires qui paraissent exacts, glissent naturellement, et se révèlent souvent subtilement faux. L’indice le plus révélateur ? Cette « homogénéité entropique » : une régularité presque parfaite du rythme lexical et syntaxique que l’humain, lui, maintient longtemps.
Certains esprits ingénieux diront qu’il suffit d’interdire à la machine l’usage de ces figures. Pourtant, la réalité est plus subtile : priver la machine de ces éléments ne corrige rien, cela déplace simplement le problème. Quid d’un LLM, prompté par API et affiné par des ressources stylistiques externes ? Peu s’y essaient. Et je crois qu’en vérité, on ne s’affranchit pas si facilement des paysages statistiques !
Surtout quand c’est nous qui nous perdons dans ces grands horizons. Car, ironiquement, ce n’est pas toujours la machine qui est en cause, mais l’humain lui-même. À force d’avaler du texte généré, certains en prennent les tics. Et comme l’explique Kaplan :
“Cette régularisation de la langue était prévisible. Elle résulte de la logique économique d’accumulation, de modélisation et de médiation propre au capitalisme linguistique”
C’est dans ce contexte paradoxal, où l’humain se met à ressembler à la machine qu’il redoute, que ces outils de détection recèlent un pouvoir qu’on sous-estime : ils permettent de comprendre.

Comprendre ce qui est machinique et statistique… pour mieux s’en libérer ? Pour se singulariser ?
Alors, peut-être, réinvestirons-nous dans de bons copywriters, dans des ateliers d’écriture qui nous donneront le goût du texte vivant – peut-être même délaisserons-nous les TikTok pour relire nos classiques.
Ou bien nous réinventerons la roue, avec des outils d’IA dédiés à l’écriture, pour mieux nous aider à développer notre voix. Après tout, si le texte est solide, animé par une vraie intention, et qu’on ne distingue pas la machine de l’humain, est-ce vraiment un problème ?
Car pendant que la machine apprend, nous, parfois, nous désapprenons. Et c’est peut-être justement là que réside la différence la plus subtile, et la plus humaine, entre l’intelligence et l’intelligence artificielle.
👉 Voir tous les billets de Marie Dollé sur sa newsletter substack « In bed with Tech »
Topics
TOUS LES MATINS, RECEVEZ UNE DOSE D'ADTECH, D'EVENEMENTS, D'INNOVATIONS, MEDIA, MARKETING...
Je découvre les newsletters Minted !